Download Certified Associate Developer for Apache Spark.CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK.ExamTopics.2026-01-04.186q.vcex
| Vendor: | Databricks |
| Exam Code: | CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK |
| Exam Name: | Certified Associate Developer for Apache Spark |
| Date: | Jan 04, 2026 |
| File Size: | 2 MB |
How to open VCEX files?
Files with VCEX extension can be opened by ProfExam Simulator.
Purchase
Coupon: TAURUSSIM_20OFF
Discount: 20%





Demo Questions
Question 1
Which of the following statements about Spark’s stability is incorrect?
- Spark is designed to support the loss of any set of worker nodes.
- Spark will rerun any failed tasks due to failed worker nodes.
- Spark will recompute data cached on failed worker nodes.
- Spark will spill data to disk if it does not fit in memory.
- Spark will reassign the driver to a worker node if the driver’s node fails.
Correct answer: E
Explanation:
E: 19 - Mosted E: 19 - Mosted
Question 2
Which of the following operations fails to return a DataFrame with no duplicate rows?
- DataFrame.dropDuplicates()
- DataFrame.distinct()
- DataFrame.drop_duplicates()
- DataFrame.drop_duplicates(subset = None)
- DataFrame.drop_duplicates(subset = "all")
Correct answer: E
Explanation:
B: 1E: 24 - Mosted B: 1E: 24 - Mosted
Question 3
Of the following situations, in which will it be most advantageous to store DataFrame df at the MEMORY_AND_DISK storage level rather than the MEMORY_ONLY storage level?
- When all of the computed data in DataFrame df can fit into memory.
- When the memory is full and it’s faster to recompute all the data in DataFrame df rather than read it from disk.
- When it’s faster to recompute all the data in DataFrame df that cannot fit into memory based on its logical plan rather than read it from disk.
- When it’s faster to read all the computed data in DataFrame df that cannot fit into memory from disk rather than recompute it based on its logical plan.
- The storage level MENORY_ONLY will always be more advantageous because it’s faster to read data from memory than it is to read data from disk.
Correct answer: D
Explanation:
D: 4 - Mosted D: 4 - Mosted
Question 4
Which of the following cluster configurations is most likely to experience an out-of-memory error in response to data skew in a single partition?
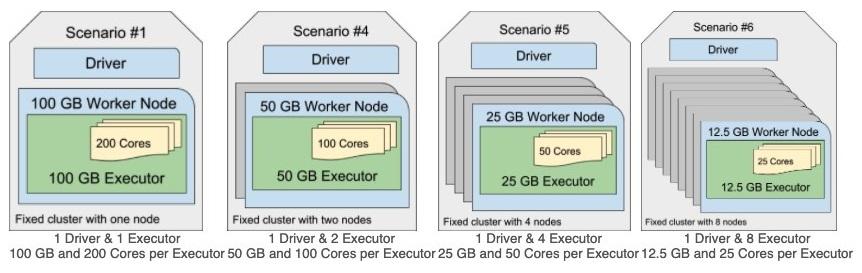
Note: each configuration has roughly the same compute power using 100 GB of RAM and 200 cores.
- Scenario #4
- Scenario #5
- Scenario #6
- More information is needed to determine an answer.
- Scenario #1
Correct answer: C
Explanation:
C: 16 - MostedE: 2 C: 16 - MostedE: 2
Question 5
Which of the following describes the relationship between nodes and executors?
- Executors and nodes are not related.
- Anode is a processing engine running on an executor.
- An executor is a processing engine running on a node.
- There are always the same number of executors and nodes.
- There are always more nodes than executors.
Correct answer: C
Explanation:
C: 16 - Mosted C: 16 - Mosted
Question 6
Which of the following will occur if there are more slots than there are tasks?
- The Spark job will likely not run as efficiently as possible.
- The Spark application will fail – there must be at least as many tasks as there are slots.
- Some executors will shut down and allocate all slots on larger executors first.
- More tasks will be automatically generated to ensure all slots are being used.
- The Spark job will use just one single slot to perform all tasks.
Correct answer: A
Explanation:
A: 15 - MostedE: 2 A: 15 - MostedE: 2
Question 7
Which of the following code blocks returns a new DataFrame with column storeDescription where the pattern "Description: " has been removed from the beginning of column storeDescription in DataFrame storesDF?
A sample of DataFrame storesDF is below:
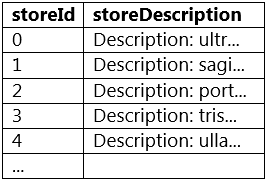
- storesDF.withColumn("storeDescription", regexp_replace(col("storeDescription"), "^Description: "))
- storesDF.withColumn("storeDescription", col("storeDescription").regexp_replace("^Description: ", ""))
- storesDF.withColumn("storeDescription", regexp_extract(col("storeDescription"), "^Description: ", ""))
- storesDF.withColumn("storeDescription", regexp_replace("storeDescription", "^Description: ", ""))
- storesDF.withColumn("storeDescription", regexp_replace(col("storeDescription"), "^Description: ", ""))
Correct answer: E
Explanation:
A: 2D: 5E: 9 - Mosted A: 2D: 5E: 9 - Mosted
Question 8
The code block shown contains an error. The code block is intended to return a new DataFrame where column sqft from DataFrame storesDF has had its missing values replaced with the value 30,000. Identify the error.
A sample of DataFrame storesDF is displayed below:
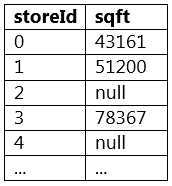
Code block:
storesDF.na.fill(30000, col("sqft"))
- The argument to the subset parameter of fill() should be a string column name or a list of string column names rather than a Column object.
- The na.fill() operation does not work and should be replaced by the dropna() operation.
- he argument to the subset parameter of fill() should be a the numerical position of the column rather than a Column object.
- The na.fill() operation does not work and should be replaced by the nafill() operation.
- The na.fill() operation does not work and should be replaced by the fillna() operation.
Correct answer: A
Explanation:
A: 5 - MostedE: 1 A: 5 - MostedE: 1
Question 9
Which of the following code blocks will most quickly return an approximation for the number of distinct values in column division in DataFrame storesDF?
- storesDF.agg(approx_count_distinct(col("division")).alias("divisionDistinct"))
- storesDF.agg(approx_count_distinct(col("division"), 0.01).alias("divisionDistinct"))
- storesDF.agg(approx_count_distinct(col("division"), 0.15).alias("divisionDistinct"))
- storesDF.agg(approx_count_distinct(col("division"), 0.0).alias("divisionDistinct"))
- storesDF.agg(approx_count_distinct(col("division"), 0.05).alias("divisionDistinct"))
Correct answer: C
Explanation:
B: 5C: 12 - Mosted B: 5C: 12 - Mosted
Question 10
Which of the following code blocks returns a DataFrame where column storeCategory from DataFrame storesDF is split at the underscore character into column storeValueCategory and column storeSizeCategory?
A sample of DataFrame storesDF is displayed below:
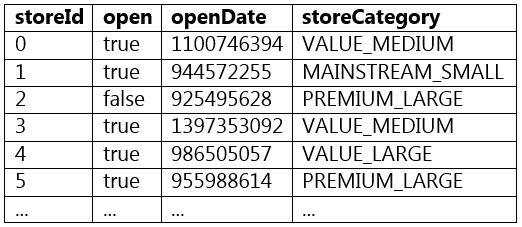
- (storesDF.withColumn("storeValueCategory", split(col("storeCategory"), "_")[1]).withColumn("storeSizeCategory", split(col("storeCategory"), "_")[2]))
- (storesDF.withColumn("storeValueCategory", col("storeCategory").split("_")[0]).withColumn("storeSizeCategory", col("storeCategory").split("_")[1]))
- (storesDF.withColumn("storeValueCategory", split(col("storeCategory"), "_")[0]).withColumn("storeSizeCategory", split(col("storeCategory"), "_")[1]))
- (storesDF.withColumn("storeValueCategory", split("storeCategory", "_")[0]).withColumn("storeSizeCategory", split("storeCategory", "_")[1]))
- (storesDF.withColumn("storeValueCategory", col("storeCategory").split("_")[1]).withColumn("storeSizeCategory", col("storeCategory").split("_")[2]))
Correct answer: C
Explanation:
C: 6 - Mosted C: 6 - Mosted
HOW TO OPEN VCE FILES
Use VCE Exam Simulator to open VCE files

HOW TO OPEN VCEX FILES
Use ProfExam Simulator to open VCEX files


ProfExam at a 20% markdown
You have the opportunity to purchase ProfExam at a 20% reduced price
Get Now!