Download Certified Data Engineer Associate.CERTIFIED-DATA-ENGINEER-ASSOCIATE.ExamTopics.2025-12-17.232q.tqb
| Vendor: | Databricks |
| Exam Code: | CERTIFIED-DATA-ENGINEER-ASSOCIATE |
| Exam Name: | Certified Data Engineer Associate |
| Date: | Dec 17, 2025 |
| File Size: | 5 MB |
How to open TQB files?
Files with TQB (Taurus Question Bank) extension can be opened by Taurus Exam Studio.
Purchase
Coupon: TAURUSSIM_20OFF
Discount: 20%
Demo Questions
Question 1
The data engineering team is migrating an enterprise system with thousands of tables and views into the Lakehouse. They plan to implement the target architecture using a series of bronze, silver, and gold tables. Bronze tables will almost exclusively be used by production data engineering workloads, while silver tables will be used to support both data engineering and machine learning workloads. Gold tables will largely serve business intelligence and reporting purposes. While personal identifying information (PII) exists in all tiers of data, pseudonymization and anonymization rules are in place for all data at the silver and gold levels.
The organization is interested in reducing security concerns while maximizing the ability to collaborate across diverse teams.
Which statement exemplifies best practices for implementing this system?
- Isolating tables in separate databases based on data quality tiers allows for easy permissions management through database ACLs and allows physical separation of default storage locations for managed tables.
- Because databases on Databricks are merely a logical construct, choices around database organization do not impact security or discoverability in the Lakehouse.
- Storing all production tables in a single database provides a unified view of all data assets available throughout the Lakehouse, simplifying discoverability by granting all users view privileges on this database.
- Working in the default Databricks database provides the greatest security when working with managed tables, as these will be created in the DBFS root.
Correct answer: A
Question 2
A new data engineer notices that a critical field was omitted from an application that writes its Kafka source to Delta Lake. This happened even though the critical field was in the Kafka source. That field was further missing from data written to dependent, long-term storage. The retention threshold on the Kafka service is seven days. The pipeline has been in production for three months.
Which describes how Delta Lake can help to avoid data loss of this nature in the future?
- The Delta log and Structured Streaming checkpoints record the full history of the Kafka producer.
- Delta Lake schema evolution can retroactively calculate the correct value for newly added fields, as long as the data was in the original source.
- Delta Lake automatically checks that all fields present in the source data are included in the ingestion layer.
- Ingesting all raw data and metadata from Kafka to a bronze Delta table creates a permanent, replayable history of the data state.
Correct answer: D
Question 3
Spill occurs as a result of executing various wide transformations. However, diagnosing spill requires one to proactively look for key indicators.
Where in the Spark UI are two of the primary indicators that a partition is spilling to disk?
- Stage’s detail screen and Query’s detail screen
- Stage’s detail screen and Executor’s log files
- Driver’s and Executor’s log files
- Executor’s detail screen and Executor’s log files
Correct answer: B
Question 4
Which statement describes the correct use of pyspark.sql.functions.broadcast?
- It marks a column as having low enough cardinality to properly map distinct values to available partitions, allowing a broadcast join.
- It marks a column as small enough to store in memory on all executors, allowing a broadcast join.
- It caches a copy of the indicated table on all nodes in the cluster for use in all future queries during the cluster lifetime.
- It marks a DataFrame as small enough to store in memory on all executors, allowing a broadcast join.
Correct answer: D
Question 5
A Structured Streaming job deployed to production has been experiencing delays during peak hours of the day. At present, during normal execution, each microbatch of data is processed in less than 3 seconds. During peak hours of the day, execution time for each microbatch becomes very inconsistent, sometimes exceeding 30 seconds. The streaming write is currently configured with a trigger interval of 10 seconds.
Holding all other variables constant and assuming records need to be processed in less than 10 seconds, which adjustment will meet the requirement?
- Decrease the trigger interval to 5 seconds; triggering batches more frequently allows idle executors to begin processing the next batch while longer running tasks from previous batches finish.
- Decrease the trigger interval to 5 seconds; triggering batches more frequently may prevent records from backing up and large batches from causing spill.
- The trigger interval cannot be modified without modifying the checkpoint directory; to maintain the current stream state, increase the number of shuffle partitions to maximize parallelism.
- Use the trigger once option and configure a Databricks job to execute the query every 10 seconds; this ensures all backlogged records are processed with each batch.
Correct answer: B
Question 6
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Incremental state information should be maintained for 10 minutes for late-arriving data.
Streaming DataFrame df has the following schema:
"device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT"
Code block:

Choose the response that correctly fills in the blank within the code block to complete this task.
- withWatermark("event_time", "10 minutes")
- awaitArrival("event_time", "10 minutes")
- await("event_time + ‘10 minutes'")
- slidingWindow("event_time", "10 minutes")
Correct answer: A
Question 7
A junior developer complains that the code in their notebook isn't producing the correct results in the development environment. A shared screenshot reveals that while they're using a notebook versioned with Databricks Repos, they're using a personal branch that contains old logic. The desired branch named dev-2.3.9 is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
- Use Repos to make a pull request use the Databricks REST API to update the current branch to dev-2.3.9
- Use Repos to pull changes from the remote Git repository and select the dev-2.3.9 branch.
- Use Repos to checkout the dev-2.3.9 branch and auto-resolve conflicts with the current branch
- Use Repos to merge the current branch and the dev-2.3.9 branch, then make a pull request to sync with the remote repository
Correct answer: B
Question 8
Which Python variable contains a list of directories to be searched when trying to locate required modules?
- importlib.resource_path
- sys.path
- os.path
- pypi.path
Correct answer: B
Question 9
A Delta Lake table was created with the below query:
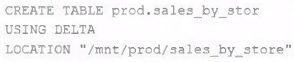
Realizing that the original query had a typographical error, the below code was executed:
ALTER TABLE prod.sales_by_stor RENAME TO prod.sales_by_store
Which result will occur after running the second command?
- The table reference in the metastore is updated.
- All related files and metadata are dropped and recreated in a single ACID transaction.
- The table name change is recorded in the Delta transaction log.
- A new Delta transaction log is created for the renamed table.
Correct answer: A
Question 10
The data engineering team maintains the following code:

Assuming that this code produces logically correct results and the data in the source table has been de-duplicated and validated, which statement describes what will occur when this code is executed?
- The silver_customer_sales table will be overwritten by aggregated values calculated from all records in the gold_customer_lifetime_sales_summary table as a batch job.
- A batch job will update the gold_customer_lifetime_sales_summary table, replacing only those rows that have different values than the current version of the table, using customer_id as the primary key.
- The gold_customer_lifetime_sales_summary table will be overwritten by aggregated values calculated from all records in the silver_customer_sales table as a batch job.
- An incremental job will detect if new rows have been written to the silver_customer_sales table; if new rows are detected, all aggregates will be recalculated and used to overwrite the gold_customer_lifetime_sales_summary table.
Correct answer: C
HOW TO OPEN VCE FILES
Use VCE Exam Simulator to open VCE files

HOW TO OPEN VCEX FILES
Use ProfExam Simulator to open VCEX files


ProfExam at a 20% markdown
You have the opportunity to purchase ProfExam at a 20% reduced price
Get Now!