Download Implementing Data Engineering Solutions Using Azure Databricks.DP-750.DumpsBase.2026-06-23.20q.vcex
| Vendor: | Microsoft |
| Exam Code: | DP-750 |
| Exam Name: | Implementing Data Engineering Solutions Using Azure Databricks |
| Date: | Jun 23, 2026 |
| File Size: | 977 KB |
How to open VCEX files?
Files with VCEX extension can be opened by ProfExam Simulator.
Purchase
Coupon: TAURUSSIM_20OFF
Discount: 20%





Demo Questions
Question 1
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a managed Delta table named Table1. Table1 stores customer data.
You need to implement a data retention solution that meets the following requirements:
- Deleted data must be retained for 30 days to support audits.
- Deleted data that is older than 30 days must be removed permanently.
- The solution must minimize administrative effort
Which two properties should you configure? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- delta.timeUntilArchived
- delta.enableDeletionVectors
- delta.logRetentionDuration
- delta.deletedFileRetentionDuration
- delta.autoOptimize.autoCompact
Correct answer: A
Question 2
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to implement a data lifecycle and expiration solution that meets the following requirements:
- Transaction logs and deleted data files that are older than 90 days must be removed from Delta tables to reclaim storage.
- All the tables must remain available for querying during the cleanup process.
- Administrative effort must be minimized.
What should you do for each requirement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

Correct answer: To work with this question, an Exam Simulator is required.
Explanation:
Box 1: Set deletedFileRetentionDuration to 90.The most important property to set to 90 is deletedFileRetentionDuration.The delta.deletedFileRetentionDuration table property explicitly dictates the safety threshold used by the VACUUM command. Setting this to 90 days ensures that VACUUM will physically remove data files that have been logically deleted or unreferenced in the transaction log for more than 90 days to reclaim storage.Incorrect:UntilArchivedThis is not a Delta table retention property. It is a conceptual flag or cloud lifecycle strategy but does not directly govern the behavior of the VACUUM command.logRetentionDurationThe delta.logRetentionDuration property controls how long the table history and transaction log entries are kept, which defaults to 30 days. While you should ideally keep it equal to or greater than the deleted file retention (e.g., matching it at 90 days), it governs metadata cleanup rather than the physical removal of unreferenced data files targeted by the VACUUM command.Box 2: Run the VACUUM command.Execute the VACUUM table_name command. This deletes the actual physical files from your cloud storage to reclaim space. Tables remain online and fully queryable during this process.Reference: https://learn.microsoft.com/en-us/azure/databricks/sql/language-manual/delta-vacuum Box 1: Set deletedFileRetentionDuration to 90.
The most important property to set to 90 is deletedFileRetentionDuration.
The delta.deletedFileRetentionDuration table property explicitly dictates the safety threshold used by the VACUUM command. Setting this to 90 days ensures that VACUUM will physically remove data files that have been logically deleted or unreferenced in the transaction log for more than 90 days to reclaim storage.
Incorrect:
UntilArchived
This is not a Delta table retention property. It is a conceptual flag or cloud lifecycle strategy but does not directly govern the behavior of the VACUUM command.
logRetentionDuration
The delta.logRetentionDuration property controls how long the table history and transaction log entries are kept, which defaults to 30 days. While you should ideally keep it equal to or greater than the deleted file retention (e.g., matching it at 90 days), it governs metadata cleanup rather than the physical removal of unreferenced data files targeted by the VACUUM command.
Box 2: Run the VACUUM command.
Execute the VACUUM table_name command. This deletes the actual physical files from your cloud storage to reclaim space. Tables remain online and fully queryable during this process.
Reference: https://learn.microsoft.com/en-us/azure/databricks/sql/language-manual/delta-vacuum
Question 3
You have an Azure Databricks workspace that is attached to a Unity Catalog metastore named metastore1, metastore1 contains a catalog named catalog1.
You need to create a new schema named schema2 that meets the following requirements:
- Is contained in catalog1
- Uses abfss://[email protected]/data as the managed location
Which SQL statement should you execute?
- CREATE SCHEMA catalog1.schema2LOCATION ‘abfss://[email protected]/data’;
- CREATE SCHEMA catalog1.schema2MANAGED LOCATION ‘abfss://[email protected]/ data’;
- CREATE CATALOG schema2MANAGED LOCATION ‘abfss://[email protected]/ data’;
- CREATE SCHEMA catalog1.schema2WITH DBPROPERTIES (LOCATION-’abfss://[email protected]/data’);
Correct answer: B
Explanation:
To create a new schema with a specific managed location in Azure Databricks Unity Catalog, use the CREATE SCHEMA command.CREATE SCHEMA catalog_name.schema_nameMANAGED LOCATION 'abfss://[email protected]/data';Catalog Name: Replace catalog_name with your existing catalog.Schema Name: Replace schema_name with your desired new schema name.Quotes: The storage path must be enclosed in single quotes.Privileges: You must have CREATE SCHEMA privileges on the parent catalog and ownership (or adequate permissions) on the external location.Reference: https://dev.to/encorepartners/creating-your-first-catalog-schema-and-tables-in-databricks-20p3 To create a new schema with a specific managed location in Azure Databricks Unity Catalog, use the CREATE SCHEMA command.
CREATE SCHEMA catalog_name.schema_name
MANAGED LOCATION 'abfss://[email protected]/data';
Catalog Name: Replace catalog_name with your existing catalog.
Schema Name: Replace schema_name with your desired new schema name.Quotes: The storage path must be enclosed in single quotes.
Privileges: You must have CREATE SCHEMA privileges on the parent catalog and ownership (or adequate permissions) on the external location.
Reference: https://dev.to/encorepartners/creating-your-first-catalog-schema-and-tables-in-databricks-20p3
Question 4
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to ensure that data lineage is captured and can be reviewed for tables accessed by Databricks notebooks and jobs. The solution must minimize administrative effort.
Which compute configuration should you use to capture the data lineage and what should you use to review the data lineage? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
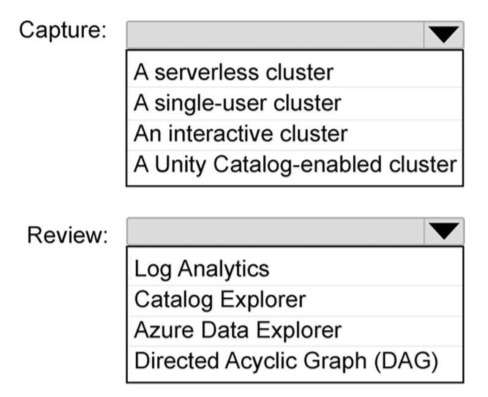
Correct answer: To work with this question, an Exam Simulator is required.
Explanation:
Box 1: A Serverless clusterTo capture automated data lineage via Unity Catalog for both Databricks notebooks and jobs with low administrative overhead, you should use Serverless compute (or Shared access mode clusters if serverless is unavailable).Recommended Compute OptionsServerless Compute (Highly Recommended):This option completely minimizes administrative overhead. It requires no infrastructure management, scales automatically, starts instantly, and captures lineage inherently for both Databricks Notebooks and Jobs.Box 2: Catalog ExplorerTo review data lineage in an Azure Databricks workspace enabled for Unity Catalog, you should use Catalog Explorer.Because you are using Unity Catalog and Serverless compute, table-level and column-level data lineage is automatically captured for notebooks and jobs without any manual configuration or administrative overhead.View Lineage in Catalog ExplorerYou can visually explore how data flows between tables by navigating through the Azure Databricks user interface:Open the Catalog icon in the sidebar.Select the desired catalog, schema, and table.Click the Lineage tab.Click See lineage graph to view an interactive map of upstream and downstream dependencies.Reference:https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-catalog/best-practiceshttps://kanerika.com/blogs/databricks-data-lineage/ Box 1: A Serverless cluster
To capture automated data lineage via Unity Catalog for both Databricks notebooks and jobs with low administrative overhead, you should use Serverless compute (or Shared access mode clusters if serverless is unavailable).
Recommended Compute Options
Serverless Compute (Highly Recommended):
This option completely minimizes administrative overhead. It requires no infrastructure management, scales automatically, starts instantly, and captures lineage inherently for both Databricks Notebooks and Jobs.
Box 2: Catalog Explorer
To review data lineage in an Azure Databricks workspace enabled for Unity Catalog, you should use Catalog Explorer.
Because you are using Unity Catalog and Serverless compute, table-level and column-level data lineage is automatically captured for notebooks and jobs without any manual configuration or administrative overhead.
View Lineage in Catalog Explorer
You can visually explore how data flows between tables by navigating through the Azure Databricks user interface:
Open the Catalog icon in the sidebar.
Select the desired catalog, schema, and table.
Click the Lineage tab.
Click See lineage graph to view an interactive map of upstream and downstream dependencies.
Reference:
https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-catalog/best-practices
https://kanerika.com/blogs/databricks-data-lineage/
Question 5
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a catalog named catalog1.
You have a group named group1.
You plan to create a schema named schema1 in catalog1.
You need to ensure that group1 meets the following requirements:
- Can create tables in schema1
- Can modify and query tables
- Cannot grant permissions for the schema and its objects
How should you complete the SQL statements? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

Correct answer: To work with this question, an Exam Simulator is required.
Explanation:
Box 1: USAGE, CREATE TABLEUSAGE, CREATE TABLE allows entering the schema and creating new tables.Box 2: TO ROLE group1Reference: https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-catalog/access-control/privileges-reference Box 1: USAGE, CREATE TABLE
USAGE, CREATE TABLE allows entering the schema and creating new tables.
Box 2: TO ROLE group1
Reference: https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-catalog/access-control/privileges-reference
Question 6
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a managed Delta table named Table1.
Table1 is written by batch jobs every hour and is queried frequently by filtering two columns named Customerid and EventDate.
You expect Table1 to grow significantly over time.
The rows in Table1 are frequently updated and deleted to support compliance requests.
You need to keep query performance consistent as Table1 grows. The solution must minimize update and deletion effort.
What should you include in the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

Correct answer: To work with this question, an Exam Simulator is required.
Explanation:
Box 1: Liquid ClusteringTo optimize query performance, implement:To optimize query performance for a rapidly growing, frequently updated managed Delta table filtered by customer and date in Unity Catalog, you must implement Liquid Clustering on both the customer and date columns, while running regular OPTIMIZE and VACUUM maintenance.Liquid Clustering replaces traditional partitioning and Z-Ordering, drastically improving performance for tables with high-frequency write, update, and delete workloads.Box 2: Enable deletion vectors.To optimize updates and deletions:Write and Execution StrategiesUse Deletion Vectors: Ensure Deletion Vectors are enabled (default in Databricks Runtime 12.1+). They record deletes and updates in a separate lightweight file instead of rewriting the entire data file immediately.Leverage MERGE INTO: Execute updates and deletions in a single atomic batch using the MERGE command. Ensure your ON search condition explicitly includes filters for both the customer and date columns to trigger file pruning.Reference: https://blog.devgenius.io/liquid-clustering-in-databricks-4002fddbf0beSecure and govern Unity Catalog objectsQuestion Set 1 Box 1: Liquid Clustering
To optimize query performance, implement:
To optimize query performance for a rapidly growing, frequently updated managed Delta table filtered by customer and date in Unity Catalog, you must implement Liquid Clustering on both the customer and date columns, while running regular OPTIMIZE and VACUUM maintenance.
Liquid Clustering replaces traditional partitioning and Z-Ordering, drastically improving performance for tables with high-frequency write, update, and delete workloads.
Box 2: Enable deletion vectors.
To optimize updates and deletions:
Write and Execution Strategies
Use Deletion Vectors: Ensure Deletion Vectors are enabled (default in Databricks Runtime 12.1+). They record deletes and updates in a separate lightweight file instead of rewriting the entire data file immediately.
Leverage MERGE INTO: Execute updates and deletions in a single atomic batch using the MERGE command. Ensure your ON search condition explicitly includes filters for both the customer and date columns to trigger file pruning.
Reference: https://blog.devgenius.io/liquid-clustering-in-databricks-4002fddbf0be
Secure and govern Unity Catalog objects
Question Set 1
Question 7
Note: This section contains one or more sets of questions with the same scenario and problem. Each question presents a unique solution to the problem. You must determine whether the solution meets the stated goals. More than one solution in the set might solve the problem. It is also possible that none of the solutions in the set solve the problem.
After you answer a question in this section, you will NOT be able to return. As a result, these questions do not appear on the Review Screen.
You have an Azure Databricks workspace named Workspace1 that contains a lakehouse and is enabled for Unity Catalog.
You have a connection to a Microsoft SQL Server database named DB1.
You need to expose the schemas and tables of DB1 to meet the following requirements:
- The schemas and tables can be queried in Databricks.
- The schemas and tables appear alongside other Unity Catalog objects.
- The data is NOT copied into Databricks-managed storage.
Solution: You create a Lakeflow Connect pipeline and connect it to DB1.
Does this meet the goal?
- Yes
- No
Correct answer: B
Explanation:
Correct:* You create a foreign catalog in Catalog Explorer.You should create a Foreign Catalog using Lakehouse Federation.Data Copying: Lakehouse Federation queries data directly in the source SQL Server without moving or copying it.Seamless Integration: The database schemas and tables appear right inside Unity Catalog alongside your other data objects. Real-time Access: It provides immediate access to live SQL Server data.Incorrect:* You create a Databricks access connector.* You create a Lakeflow Connect pipeline and connect it to DB1.Data Copying: Lakeflow Connect is an ingestion tool that physically replicates and copies data into Databricks-managed storage (Delta tables).Storage Costs: It violates your requirement to keep data out of Databricks storage. * You create a new native catalog in Unity Catalog. Note:To expose the external SQL Server database in Unity Catalog without copying the data, you must use Lakehouse Federation.Here are the step-by-step actions you need to take:1. Create a ConnectionCreate a securable object in Unity Catalog that specifies the path and credentials to access the SQL Server database.Go to Catalog Explorer or use SQL.Select External Data > Connections.Create a connection using the SQL Server connection details (URL, host, port, and database credentials). *-> 2. Create a Foreign CatalogCreate a specific type of catalog in Unity Catalog that mirrors the external database.Use the CREATE FOREIGN CATALOG SQL command or the Catalog Explorer UI.Link this foreign catalog directly to the connection you created in step 1.3. Query the DataOnce the foreign catalog is created, Unity Catalog automatically syncs the schemas andtables from SQL Server.Reference: https://docs.databricks.com/gcp/en/database-objects/ Correct:
* You create a foreign catalog in Catalog Explorer.
You should create a Foreign Catalog using Lakehouse Federation.
Data Copying: Lakehouse Federation queries data directly in the source SQL Server without moving or copying it.
Seamless Integration: The database schemas and tables appear right inside Unity Catalog alongside your other data objects. Real-time Access: It provides immediate access to live SQL Server data.
Incorrect:
* You create a Databricks access connector.
* You create a Lakeflow Connect pipeline and connect it to DB1.
Data Copying: Lakeflow Connect is an ingestion tool that physically replicates and copies data into Databricks-managed storage (Delta tables).
Storage Costs: It violates your requirement to keep data out of Databricks storage. * You create a new native catalog in Unity Catalog. Note:
To expose the external SQL Server database in Unity Catalog without copying the data, you must use Lakehouse Federation.
Here are the step-by-step actions you need to take:
1. Create a Connection
Create a securable object in Unity Catalog that specifies the path and credentials to access the SQL Server database.
Go to Catalog Explorer or use SQL.
Select External Data > Connections.
Create a connection using the SQL Server connection details (URL, host, port, and database credentials). *-> 2. Create a Foreign Catalog
Create a specific type of catalog in Unity Catalog that mirrors the external database.
Use the CREATE FOREIGN CATALOG SQL command or the Catalog Explorer UI.
Link this foreign catalog directly to the connection you created in step 1.
3. Query the DataOnce the foreign catalog is created, Unity Catalog automatically syncs the schemas and
tables from SQL Server.
Reference: https://docs.databricks.com/gcp/en/database-objects/
Question 8
You have an Azure Databricks workspace named Workspace1 that is attached to a Unity Catalog metastore named metastore1.
You need to register an Azure Storage account named account1 that has a hierarchical namespace enabled as an external location. The external location must use a managed identity to authenticate to account1 and the solution must follow the principle of least privilege.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
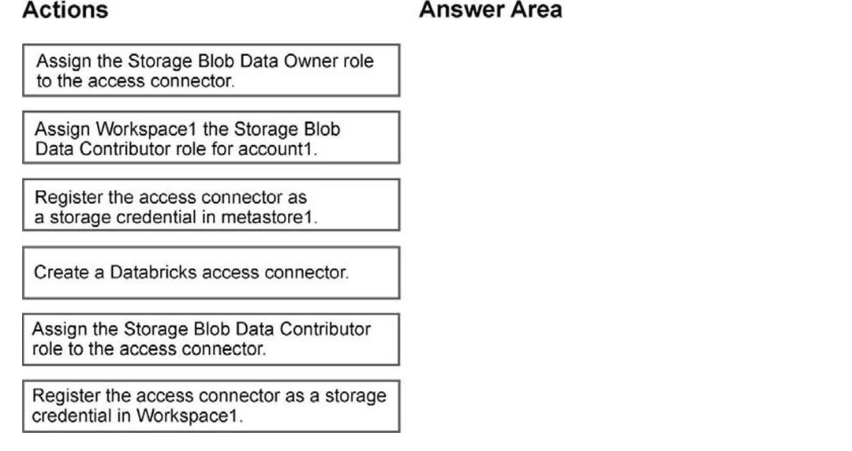
Correct answer: To work with this question, an Exam Simulator is required.
Explanation:
To register an Azure Storage account (ADLS Gen2) as an external location using a managed identity and an Access Connector under the principle of least privilege, you must complete the following configuration workflow:Step 1: Create a Databricks access ConnectorAction 1: Create an Access Connector for Azure Databricks Navigate to the Azure Portal.Create a new resource and search for Access Connector for Azure Databricks.Configure it in the same Azure region as your ADLS Gen2 storage account.Ensure the System-assigned managed identity status is turned On (or attach a specific user-assigned managed identity). Once deployed, navigate to its properties and copy the Resource ID.Step 2: Assign Workspace1 the Storage Blob Data Contributor role for account1.Action 2: Configure Least-Privilege IAM Roles on the Storage Account Navigate to your hierarchical namespace-enabled Azure Storage Account. Open Access Control (IAM) and click Add role assignment. *-> Assign the Storage Blob Data Contributor role.Note on Least Privilege: To enforce true least privilege, avoid assigning this role at the entire storage account level. Instead, scope this role assignment specifically to the target container inside the storage account.Select Managed identity as the assignee type and select your Access Connector.Step 3: Register the access connector as a storage credential in metastore1Action 3: The Databricks access connector must be registered in the metastore (via a Unity Catalog Storage Credential), not in the individual workspace.Centralized Security: Unity Catalog manages security at the account/metastore level.Cross-Workspace Access: Registering it in the metastore allows the credential to be safely shared across multiple workspaces attached to that same metastore.Object Hierarchy: In Unity Catalog, an External Location relies on a Storage Credential. Both are metastore-level securable objects.Reference: https://community.databricks.com/t5/data-governance/unity-catalog-error-creating-table-errorclass-invalid-state/td-p/10009 To register an Azure Storage account (ADLS Gen2) as an external location using a managed identity and an Access Connector under the principle of least privilege, you must complete the following configuration workflow:
Step 1: Create a Databricks access Connector
Action 1: Create an Access Connector for Azure Databricks Navigate to the Azure Portal.
Create a new resource and search for Access Connector for Azure Databricks.
Configure it in the same Azure region as your ADLS Gen2 storage account.
Ensure the System-assigned managed identity status is turned On (or attach a specific user-assigned managed identity). Once deployed, navigate to its properties and copy the Resource ID.
Step 2: Assign Workspace1 the Storage Blob Data Contributor role for account1.
Action 2: Configure Least-Privilege IAM Roles on the Storage Account Navigate to your hierarchical namespace-enabled Azure Storage Account. Open Access Control (IAM) and click Add role assignment. *-> Assign the Storage Blob Data Contributor role.
Note on Least Privilege: To enforce true least privilege, avoid assigning this role at the entire storage account level. Instead, scope this role assignment specifically to the target container inside the storage account.
Select Managed identity as the assignee type and select your Access Connector.
Step 3: Register the access connector as a storage credential in metastore1
Action 3: The Databricks access connector must be registered in the metastore (via a Unity Catalog Storage Credential), not in the individual workspace.
Centralized Security: Unity Catalog manages security at the account/metastore level.
Cross-Workspace Access: Registering it in the metastore allows the credential to be safely shared across multiple workspaces attached to that same metastore.
Object Hierarchy: In Unity Catalog, an External Location relies on a Storage Credential. Both are metastore-level securable objects.
Reference: https://community.databricks.com/t5/data-governance/unity-catalog-error-creating-table-errorclass-invalid-state/td-p/10009
Question 9
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains two catalogs
named Catalog1 and Catalog2.
An external application uses a service principal named SP1 to connect to a SQL warehouse.
You need to ensure that SP1 can query the data in Catalog1 and Catalog2. The solution must follow the principle of least privilege.
Which permissions should you grant to SP1 for the catalogs?
- USE SCHEMA and SELECT
- USE CATALOG and SELECT
- USE CATALOG, USE SCHEMA, and SELECT
- USE CATALOG and USE SCHEMA
Correct answer: C
Explanation:
To ensure a service principal can query data in two specific catalogs while maintaining the principle of least privilege, you must assign the following permissions for each catalog:Unified Catalog PermissionsUSE CATALOG on the specific catalog: This is a prerequisite that allows the principal to see the catalog and its child objects.USE SCHEMA on the schemas containing the data: This allows the principal to interact with the schemas within that catalog.SELECT on the specific tables or views: This provides the actual read access required to query the data.Reference: https://learn.microsoft.com/en-us/purview/data-governance-roles-permissions To ensure a service principal can query data in two specific catalogs while maintaining the principle of least privilege, you must assign the following permissions for each catalog:
Unified Catalog Permissions
USE CATALOG on the specific catalog: This is a prerequisite that allows the principal to see the catalog and its child objects.
USE SCHEMA on the schemas containing the data: This allows the principal to interact with the schemas within that catalog.
SELECT on the specific tables or views: This provides the actual read access required to query the data.
Reference: https://learn.microsoft.com/en-us/purview/data-governance-roles-permissions
Question 10
You have an Azure Databricks workspace.
You have an Azure key vault named kv-secure that stores a secret named storage Key. The value of storage Key is managed and updated by the cloud security team at your company.
You need to enable a Databricks notebook named Notebook1 to retrieve the value of storage Key securely at runtime. The solution must follow the principle of least privilege and always retrieve the latest value.
What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

Correct answer: To work with this question, an Exam Simulator is required.
Explanation:
Box 1: A Key Vault-backed secret scopeTo securely expose the storage Key to your Databricks notebook while adhering to the principle of least privilege, use an Azure Key Vault-backed secret scope.This approach acts as a read-only bridge to your Key Vault, ensuring the security team manages the key centrally, while the notebook always fetches the latest version dynamically.Secret Exposure: Notebooks reference the secret by an alias name.Always Updated: Databricks fetches the secret directly from Key Vault at runtime, ensuring it always gets the latest version updated by your security team.Least Privilege: Access can be restricted to specific users or groups using Databricks Access Control Lists (ACLs).Box 2: dbutils.secrets.getUse an Azure Key Vault-backed secret scope in combination with the dbutils.secrets.get function.This approach centralizes the secret's management for your security team, follows the principle of least privilege through Azure IAM, and ensures your notebook always fetches the latest runtime value.Run this specific command inside your Databricks Python notebook:storage_key = dbutils.secrets.get(scope="your-scope-name", key="storageKey")Reference: https://medium.com/@techgeorge/how-to-integrate-databricks-with-azure-key-vault-using-rbac-instead-of-access-policies-972e8c1c2971 Box 1: A Key Vault-backed secret scope
To securely expose the storage Key to your Databricks notebook while adhering to the principle of least privilege, use an Azure Key Vault-backed secret scope.
This approach acts as a read-only bridge to your Key Vault, ensuring the security team manages the key centrally, while the notebook always fetches the latest version dynamically.
Secret Exposure: Notebooks reference the secret by an alias name.
Always Updated: Databricks fetches the secret directly from Key Vault at runtime, ensuring it always gets the latest version updated by your security team.
Least Privilege: Access can be restricted to specific users or groups using Databricks Access Control Lists (ACLs).
Box 2: dbutils.secrets.get
Use an Azure Key Vault-backed secret scope in combination with the dbutils.secrets.get function.
This approach centralizes the secret's management for your security team, follows the principle of least privilege through Azure IAM, and ensures your notebook always fetches the latest runtime value.
Run this specific command inside your Databricks Python notebook:
storage_key = dbutils.secrets.get(scope="your-scope-name", key="storageKey")
Reference: https://medium.com/@techgeorge/how-to-integrate-databricks-with-azure-key-vault-using-rbac-instead-of-access-policies-972e8c1c2971
Question 11
Set up and configure an Azure Databricks environment
Testlet 1
This is a case study. Case studies are not timed separately from other exam sections. You can use as much exam time as you would like to complete each case study. However, there might be additional case studies or other exam sections. Manage your time to ensure that you can complete all the exam sections in the time provided. Pay attention to the Exam Progress at the top of the screen so you have sufficient time to complete any exam sections that follow this case study.
To answer the case study questions, you will need to reference information that is provided in the case. Case studies and associated questions might contain exhibits or other resources that provide more information about the scenario described in the case. Information provided in an individual question does not apply to the other questions in the case study.
A Review Screen will appear at the end of this case study. From the Review Screen, you can review and change your answers before you move to the next exam section. After you leave this case study, you will NOT be able to return to it.
To start the case study
To display the first question in this case study, select the “Next” button. To the left of the question, a menu provides links to information such as business requirements, the existing environment, and problem statements. Please read through all this information before answering any questions. When you are ready to answer a question, select the “Question” button to return to the question.
Overview
Company Information
Contoso, Inc. is a renewable energy provider that operates solar and wind farms across North America.
Existing Environment
Azure Environment
Contoso has a single Azure Databricks workspace named Workspace1 in the West US Azure region.
Workspace1 is enabled for Unity Catalog.
Workspace1 contains all-purpose clusters for both development and production workloads.
The company's Azure environment contains:
- In the West US, Central US, and East US Azure regions, Azure event hubs that stream telemetry data and an Azure Data Lake Storage Gen2 account in each region for each hub
- A single Azure SQL database in the West US region that hosts enterprise resource planning (ERP) data
- An Azure Database for PostgreSQL server in the West US region that stores operational maintenance data
Data Environment
Contoso ingests the following operational and business data:
- Telemetry data: More than 40,000 IoT sensors across 28 sites emit JSON telemetry events every few seconds. Each site sends the events to the nearest event hub, which writes the data into the corresponding Data Lake Storage Gen2 account. These files frequently experience schema drift.
- Maintenance logs: Maintenance systems generate historical repair logs, daily incremental updates, technician notes, and unstructured attachments that are stored in the Data Lake Storage Gen2 accounts.
- Operational maintenance data: Structured operational maintenance data is stored on the Azure Database for PostgreSQL server.
- External weather data: Hourly weather forecasts are retrieved from a REST API and written to the Data Lake Storage Gen2 accounts.
- ERP data: Daily CSV extracts of 50 to 100 GB contain equipment metadata, work orders, and purchase order information.
Problem Statements
The company’s existing analytics environment has several issues:
Ingestion
- Telemetry pipelines fall behind during peak loads.
- Telemetry ingestion fails when schema drift occurs.
- Streaming pipelines reprocess events after a pipeline restarts.
Compute
- Production and development workloads run on the same all-purpose clusters.
- Production and development workloads do NOT support autoscaling or workload isolation.
Governance
- The ERP data is duplicated across systems and development teams.
- Naming conventions are inconsistent across development teams, regions, and products.
- Ownership of the IoT sensors changes over time, and analysts must track the full history of the ownership.
- Occasionally, equipment manufacturers must correct data-entry mistakes in equipment names.
Historical values are NOT required.
Pipeline operations
- Pipelines lack resiliency, alerting, and centralized scheduling.
Requirements
Planned Changes
Contoso plans to implement the following changes:
- Implement scalable data pipeline orchestration.
- Create a managed analytics catalog in Unity Catalog.
- Implement a consistent approach to creating curated datasets.
- Establish a centralized governance model across ingestion, cleansed, and curated layers.
- Grant data engineers access to the ERP tables by using minimal development effort.
- Adopt a compute strategy that isolates production workloads and supports autoscaling.
- Adopt a slowly changing dimension (SCD) approach to address current data modeling issues.
Technical Requirements
Contoso identifies the following environment and compute requirements:
- Ensure that production ingestion workloads run on compute clusters that can scale automatically during telemetry spikes.
- Provide fast and consistent performance for business intelligence (BI) workloads.
- Prevent development activity from affecting production pipelines.
- Production ingestion workloads must run as scheduled, non-interactive pipelines rather than on shared interactive development clusters.
Contoso identifies the following data ingestion and processing requirements:
- Auto-scale ingestion pipelines to handle bursty workloads.
- Handle schema drift for the maintenance and telemetry data.
- Ingest file-based telemetry data by using minimal operational effort.
- Store all the ingested data in a format that supports incremental processing.
- Support the continuous ingestion of telemetry data from the event hubs by using exactly-once semantics.
- Support the ingestion of the structured maintenance data from the Azure Database for PostgreSQL server.
- Build a new telemetry pipeline that ingests raw events from the event hubs, cleanses the data, and publishes curated tables to Unity Catalog.
- Ensure that the Apache Spark Structured Streaming pipelines reading from the event hubs write the data into a managed Delta table named telemetry.raw_events. The pipelines must support schema drift and resume processing after failures without reprocessing the data.
Contoso identifies the following data modeling and optimization requirements:
- Build curated tables that standardize business logic.
- Overwrite equipment metadata attributes, such as name, manufacturer, model, and commissioning date, when the attributes change. Historical values are NOT required.
Contoso identifies the following pipeline deployment and operation requirements:
- Orchestrate multi-step ingestion and transformation workflows.
- Define a clear execution order and dependencies.
- Automatically retry failed steps and notify operators.
- Schedule ingestion and transformation workloads consistently.
Governance Requirements
Contoso identifies the following governance requirements:
- Centralize the metadata catalog.
- Provide isolated development areas that follow standard naming conventions.
- Establish a consistent structure for organizing raw, cleansed, and curated data.
- Provide a read-only mechanism to reference the ERP data through a foreign catalog.
Business Requirements
Contoso identifies the following business requirements:
- Improve ingestion reliability and reduce operational effort.
- Standardize data definitions across development teams.
You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
- Move the ingestion pipelines to shared compute.
- Enable Photon acceleration for a job compute cluster.
- Increase an all-purpose cluster to a larger fixed node type.
- Disable autoscaling for a job compute cluster.
Correct answer: B
Explanation:
Enabling Photon acceleration on a job compute cluster is the best option. It significantly speeds up data engineering pipelines, handles JSON file ingestion seamlessly, and optimizes cost-efficiency for bursty production workloads, which are key for processing rapidly arriving IoT sensor events.Enable Photon acceleration for a job compute cluster:Databricks Auto Loader is designed for low-latency, high-volume file ingestion. Running Auto Loader on a job compute cluster provides the lowest operational cost because job clusters are billed at a much lower rate than all-purpose clusters.Enabling Photon acceleration heavily optimizes the ingestion, parsing, and processing of raw JSON data strings, allowing the cluster to handle bursty workloads faster and auto-scale more efficiently.Scenario, Data Environment, Contoso ingests the following operational and business data: Telemetry data: More than 40,000 IoT sensors across 28 sites emit JSON telemetry events every few seconds. Each site sends the events to the nearest event hub, which writes the data into the corresponding Data Lake Storage Gen2 account. These files frequently experience schema drift.Contoso identifies the following data ingestion and processing requirements:-> Auto-scale ingestion pipelines to handle bursty workloads.Handle schema drift for the maintenance and telemetry data.-> Ingest file-based telemetry data by using minimal operational effort.Reference: https://medium.com/@krthiak/10-days-of-data-engineering-interview-qna-day-5-db1c0b58bf86 Enabling Photon acceleration on a job compute cluster is the best option. It significantly speeds up data engineering pipelines, handles JSON file ingestion seamlessly, and optimizes cost-efficiency for bursty production workloads, which are key for processing rapidly arriving IoT sensor events.
Enable Photon acceleration for a job compute cluster:
Databricks Auto Loader is designed for low-latency, high-volume file ingestion. Running Auto Loader on a job compute cluster provides the lowest operational cost because job clusters are billed at a much lower rate than all-purpose clusters.
Enabling Photon acceleration heavily optimizes the ingestion, parsing, and processing of raw JSON data strings, allowing the cluster to handle bursty workloads faster and auto-scale more efficiently.
Scenario, Data Environment, Contoso ingests the following operational and business data: Telemetry data: More than 40,000 IoT sensors across 28 sites emit JSON telemetry events every few seconds. Each site sends the events to the nearest event hub, which writes the data into the corresponding Data Lake Storage Gen2 account. These files frequently experience schema drift.
Contoso identifies the following data ingestion and processing requirements:
-> Auto-scale ingestion pipelines to handle bursty workloads.
Handle schema drift for the maintenance and telemetry data.
-> Ingest file-based telemetry data by using minimal operational effort.
Reference: https://medium.com/@krthiak/10-days-of-data-engineering-interview-qna-day-5-db1c0b58bf86
HOW TO OPEN VCE FILES
Use VCE Exam Simulator to open VCE files

HOW TO OPEN VCEX FILES
Use ProfExam Simulator to open VCEX files


ProfExam at a 20% markdown
You have the opportunity to purchase ProfExam at a 20% reduced price
Get Now!